Segmentation and Personas
Segments and Personas through clusters
Segments and Personas developed through analytical models will better target users based on the specific attributes that affect conversion rates. Current common methodology tends to have user experience teams developing entire personas based on subjective views rather than conversion trends based on recorded demographic and behavioral data.
The why and the how
To create both usable and accurate personas based on a Bayesian predictive model, we will need to develop a cluster analysis of our users. We then identify which attributes, in this case demographic-based, identify users who are likely or unlikely to convert. In this case we will be creating our personas based on only a single conversion event to keep the article short, however you should test out this strategy with a number of core conversion events for your organization to validate the personas developed work across the organization.
Setting up your data
When developing your initial clusters, it is best to simplify the data as we have below. For example, creating a different value for every possible income would give incredibly specific information, but it would be far less usable at a practical level. In this case, our five features with 2-3 values already produce 108 clusters. Note: For location information, there are a number of ways to group the data; you can do it based on geographical region, population density, distance to specific physical locations, and much more. Spend a little time determining how to break down your user’s location data best.

If we were to add even one more value option to each of the five features, we would jump to 576 clusters.
Once we know our different features, we then need to create a matrix of all our users with their features and whether or not they converted. This matrix has been built in a Google Sheet to help visualize.
Once complete, we run the actual Bayes Therom to understand the probability of any new user converting based on their feature information (demographics).
Reviewing impactful attributes
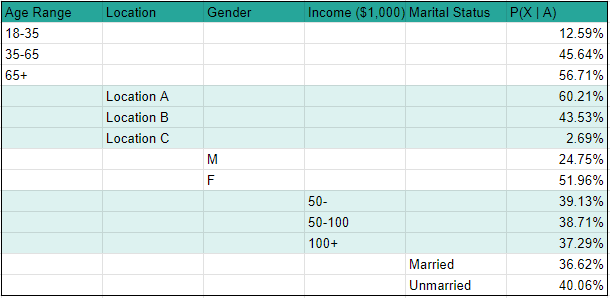
Grouping your users and identifying segments

Creating Attribute Personas
When analyzing our data, we want to look for features that significantly affect whether or not a user will convert. In this case, we see substantial effects from age, location, and gender, with minimal effects from income and marital status. We know this because of the range in probability for each feature. A wider range means a feature’s different values have more impact on the chances of converting. As you can see in image 2, income shows only a 2-point range in conversion rate, whereas location shows a 58-point range.
With this information, we can now create a decision tree to help develop the hierarchy of demographic information for our personas.
A complete visualization of our decision tree, with associated probabilities, can be found here. However, we will not include marital status or income in our personal information.
Why would we exclude specific attributes from our personas?
This comes down to two core issues—first, practicality. One of the most common reasons we develop personas is to help guide marketing, sales, and front-end dev teams in developing content or functionality. The more information we put into our personas, the more complex it becomes. Should the marketing team create a new content piece for all 108 possible combinations? Probably not. Second is informational overload and miscommunication. Although we would love to assume that we will “just do it right,” in the end, teams will always make mistakes. We want to design the personas to be simple and clear. If we were to put in information on income and marital status, it could lead a team member, who perhaps started after this was developed, to think those features were important and lead to less effective designs.
With this simplified decision tree, you can begin to focus on which user features are most telling when it comes to conversion. It can also drastically reduce the resources your physical staff and systems need to execute impactful work. Examples include purchasing a new lead list from only location A, focusing marketing efforts on mediums viewed by people 65+, avoiding strategies that target men 18-35, or from Location C.
Now that we have a better understanding of what attributes affect our user's conversion rates, we can more accurately develop user personas. It will be up to the organization to decide the best way to utilize this information, but there will be a few possible options.
NOTE: For our purposes, Location A will represent zip codes of urban areas, Location B will represent suburban areas, and Location C will represent Rural areas.
One option is to create do’s and don’ts personas. Or large overarching groups that highlight your key high and low-converting demographics.
Do
People over the age of 35 who live in a city.
Women over the age of 35 who live in the suburbs.
Don’t
People from rural communities
People under the age of 35
Another option is to stop focusing on holistic personas and focus on individual attributes instead.
Create content that anyone over the age of 35 in a city could relate to. Specifically, write some content that older women might find significant. You can also follow the same do’s and don’ts rule here by avoiding content heavily focused on camping out in the woods or modern trends and hashtag content, as your audience would not relate to that.
By creating a list of content subjects and demographics that fit our criteria, we allow for different intersections of content to be developed and tested. Perhaps we see more effective marketing when our content focuses more on location, so we build that type of content, or we may see that age is the winning subject. By not assuming how we should group our users together, we are more likely to find the most advantageous combinations.
Related Information
It is important to remember that the above decision tree does a lot more than guide our persona creation. It also allows us to understand better what to do when we have a limited understanding of our user base.
Limited user information
For example, what if the idea is posited to develop a TikTok account? Well, after doing some research, you may find that most TikTok users are under the age of 35, so the audience gathered from there as a whole would not be very useful to us. Even knowing nothing else about the users, we would get from that audience that one factor is powerful enough to guide the decision. We also have the advantage of the exact opposite. If a marketing list is purchased that guarantees all users are from major metropolitan areas, we can be confident that most of the users on that list would be likely to convert.
Incubating new audiences
In general, most organizations try to avoid targeting poor-performing audiences. However, they could be the next big leap. They represent a new market that has yet to be tapped. This is because people would, for example, say, “Let’s try to target young men from rural places,” as they are the lowest-performing group. Instead, you could incubate users with only one low-performing attribute. Target people over 65 from rural towns, target women who are under 35, instead of trying to get the entire new audience to find inroads through places where you already hold some advantages and slowly add the new clientele. This also has the benefit of being a less drastic shift. An organization may need to make significant offering changes to attract a brand-new audience but may only need to make small surface-level changes to attract slightly different audiences.