Step Gain Optimization
What are step gains?
Step Gains are large increases in conversion rates. Commonly, when we test out new content variations or strategies, we are looking for small incremental improvements, and there is nothing wrong with doing that. However, it is only one way to develop your systems. Another is to look for large steps forward in your systems, whether that be conversion funnels, site optimizations, or operational efficiencies. The methodology is the same.
Create a threshold that the new system must surpass in order to be considered a success.
Take a very small portion of your audience to test out the new system.
Iterate or scale depending on the results of the test.
The why and the how
A team may hesitate to develop a new process for many reasons. There are risks like failure to affect conversions, difficulties to develop, operational issues to maintain, and a lack of a net improvement to ROI. These factors must be considered when any change is suggested; however, with step gain tests, you can help answer these questions in a small-scale environment and then decide as an organization if the change is worth it.
Step gain tests answer questions like:
What is the expected change in conversion rates?
What challenges did you face in development?
What system changes are required to implement this new process?
Were there concerns observed that would affect the scaling or maintenance of the process?
Based on the answers above, what is the expected increase in ROI based on this new process?
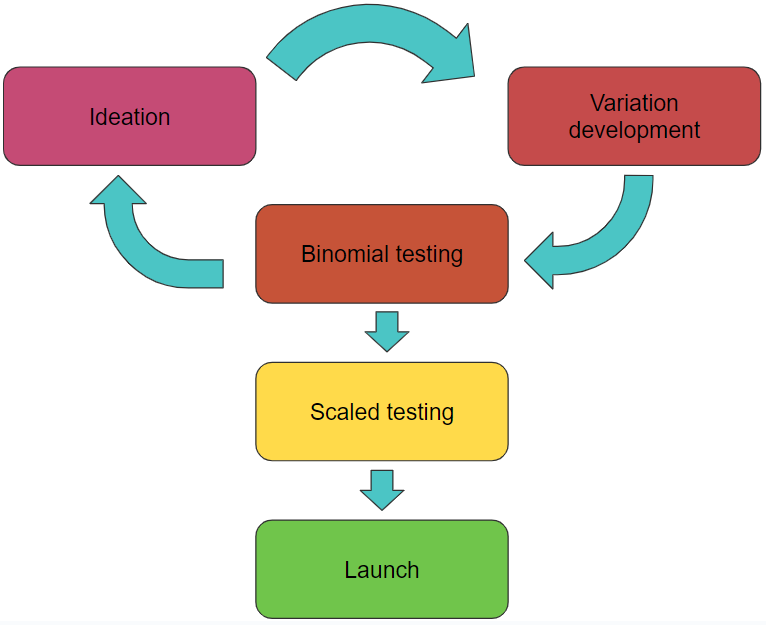
The development process will generally follow this workflow diagram.
Ideas will be ideated, then variations based on those ideas will be created, and they will enter the small-scale binomial testing stage. If they succeed, they will be scaled up; if not, we will continue to ideate.
As a reminder, tests developed for step gain optimizations should be significant in their changes. Think of these as the “big swings.” They may strike out, but it could be a home run if it hits.
It should also be noted that we do not go straight from binomial testing to full production. This step is design to weed out bad ideas before a larger scale test is run for validation.
Binomial testing
To develop this system, we will utilize binomial distribution predictions to determine the likelihood of success.
This means that instead of running a statistical significance test of a control group and a test group, we will test against a threshold.
A good comparison would be that a normal A/B test is like a sporting event between two teams. Each is attempting to be better than the other. Our binomial distribution prediction will be more like a “qualifying event” for a marathon. Each test competes only against a pre-set metric, and if it achieves that goal, it is passed through to the scaling stage.
Understanding the results of a theshold test
In a normal A/B test, we examine “statistical significance,” which is normally set to 95%. In essence, what this means is that 95% of the results were above the control or that there is a 95% chance that one variation was, in fact, better than the other. These simplified explanations of the p values in a chi-squared test work for our purposes.
Instead of doing that, we will be looking at the chance that our small test, when scaled, will meet our threshold requirements. For example, let’s say we want to improve an email series with a conversion rate of 20% to 30%. The step gain option would be to test many different variants and find one test that can immediately “step” to the desired conversion rate.
One of the most efficient ways to test these variants is with small groupings of 100 users. This audience would be large enough to produce the guiding results we seek while still small enough to have minimal effects on the business if they fail. Returning to our example of developing a system that achieves a 30% conversion rate, we can run several tests and examine the chances of that test producing the desired result below.
Here, we see several different tests, out of 100 entries each, and the number of conversions they produced. We also see the likelihood that these tests were of systems with a 30% conversion rate or better and only accidentally had this low conversion rate.

As you can intuitively see, a test with 40 out of 100 conversions is very likely to be of a system that averages a 30% conversion rate, and a test with 15 is very unlikely.

Looking at a visual representation, we see that if our test produced 30 conversions, the variation when scaled, could go in either direction, making us uncertain if it will succeed. However, if we observed 45 conversions, even if there was significant variation, it would still surpass our 30% threshold. Thus increasing the confidence.
At the most basic level, that is enough information to go off of. If the strategy for the organization is risk aversion or the ability to scale is incredibly resource intensive, then we already have the answer. Run many tests until you find one that is at least 95% likely to meet the desired goal.
However, from a pure efficiency viewpoint, this is not the optimal way to run this system. Ideally, what you would do is identify any test that, let’s say, has at least a 1 in 3 chance of succeeding, so in our case, meets 27 or 28 conversions, and then run a scaled test to determine if that measure is accurate so we can make that step gain as fast as possible.
With this methodology, you can easily understand the expected value of a new system to better determine whether or not implementation is worth it for your organization.
Related Information
Conversion Ranges
As additional information, the binomial testing also allows you to be given a 95% plus likelihood of the range of conversion rates that it will fall into when scaled.

With this additional piece of information giving us the range of conversion rates that a specific test could fall into, we can utilize our pre-test modeling strategies as an additional support mechanism for making our decisions. Perhaps even at the lower end of the bound, an organization would still see enough value to make a scaled test worth running.
AI system validation
With more teams moving to AI-supported work, it can be difficult to determine how best to implement it. However, we aim to design all our articles to integrate with AI and machine learning seamlessly. To best implement AI-generated content, you first need to test the repeatability of the AI. Can it consistently match the human content you need it to?
The primary benefits of AI are an increase in output and a decrease in cost. Therefore, we have a system that can quickly produce many variations at scale, which is exactly what the step gain test wants. Read more in our article on AI Test Optimization
Begin by choosing keywords that associate prompts. For example, you may say, write a paragraph about X, and make it “happy” and “welcoming.” Then, after reviewing the content for errors, send out the tests and review what range they all fall in. Repeat this same process with terms like “encouraging” or “informative” to understand which framing mechanism converts best. AI works through large scale repetition and validation. Setting up your systems to